CQRS Done Right: Separating Commands from Queries at Scale
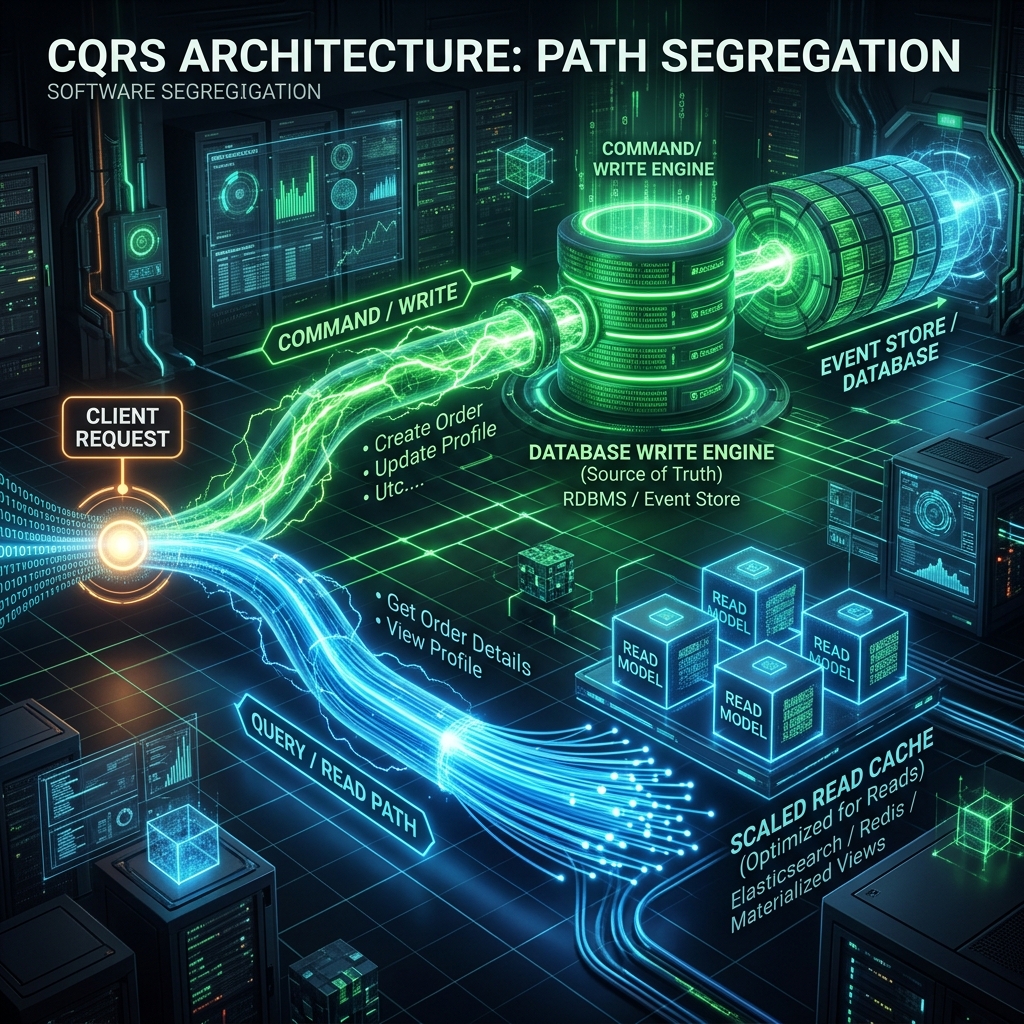
Concept
CQRS — Command Query Responsibility Segregation — is an architectural pattern that separates operations that mutate state (commands) from operations that read state (queries), using physically distinct models. The write model is optimised for enforcing business invariants with transactional consistency. The read model is optimised for query performance through denormalisation, pre-computation, and domain-specific projection.
The pattern originates from Bertrand Meyer's Command-Query Separation (CQS) principle, which states that a method should either change state or return state, but not both. CQRS applies this principle at the system architecture level: the entire command pathway and read pathway are distinct, down to (optionally) separate data stores.
At small scale, CQRS can be implemented against a single database with separate query and command layers that are logically distinct but physically co-located. The queries run against the same tables as the commands. This is the lightest-weight implementation and is appropriate for many systems. At larger scale, physical separation — a dedicated read store (Elasticsearch, Redis, a read-replica, a denormalised SQL view) fed by an event stream — provides independent scaling, tailored indexing, and the ability to serve read traffic from cache without touching the write store.
The critical insight is that most systems are read-heavy. A typical e-commerce platform might process 100 orders per second but serve 10,000 product listing requests per second. Optimising the write model for transaction throughput and the read model for query throughput independently is not premature optimisation — it is basic capacity planning.
Constraints
Write Model Invariant Enforcement
The write model's sole responsibility is to enforce business invariants. An order aggregate must ensure that an order cannot be confirmed if payment has not been captured. An inventory aggregate must ensure that stock cannot be over-reserved. These invariants must be enforced transactionally — either atomically within the aggregate boundary (for single-aggregate invariants) or through eventual consistency (for cross-aggregate invariants that tolerate temporary violation).
The write model should be expressed as domain aggregates with rich behaviour, not as anemic data containers. The command handler receives a command, loads the aggregate from the repository, calls a domain method, persists the resulting events or state change, and publishes events for downstream consumption. The aggregate's internal consistency boundary defines what can be guaranteed atomically.
Write model optimisations to avoid: eager loading of large object graphs, fetching data the command does not need, mixing read concerns (e.g., "return the updated entity after the command") into the command handler. Commands should be fire-and-confirm, not fetch-and-return.
Read Model Denormalisation and the Staleness Constraint
A read model is an explicit, denormalised representation of data shaped for a specific query. Instead of joining four normalised tables to produce a product listing with reviews, ratings, inventory status, and price — which adds latency and database load — the read model pre-computes this view as a single denormalised document per product, updated whenever any of the source entities change.
The constraint: every read model has a consistency window — the time between when a write is committed and when the read model reflects it. For a synchronously updated read model (using database triggers or within-transaction projections), this is zero. For an event-stream-fed read model, this is the sum of: event publication latency + event consumer processing latency + read model persistence latency. In well-tuned systems, this is sub-500ms. In systems under load or during consumer backlogs, it can stretch to minutes.
The consistency window must be explicitly documented and surfaced to the business. "When I place an order, how long before my order appears in my order history?" is a product question, not a purely technical one. The answer is determined by your CQRS architecture's event processing pipeline.
Projection Rebuild Strategy
Read models must be rebuildable. Business requirements change, bugs are fixed, new fields are added. When any of these require changing the projection logic, the read model must be reconstructed from the event stream or source-of-truth data. The rebuild strategy determines how disruptive this is.
Options, from most to least disruptive:
- In-place rebuild with downtime: Drop and recreate the read store. Involves read downtime. Acceptable for low-traffic internal tools.
- Shadow rebuild with blue-green cutover: Build the new projection in parallel ("shadow store") while the old one serves traffic. Once the shadow is caught up, atomically redirect read traffic. No downtime. Requires 2× storage temporarily.
- Versioned projections: Maintain multiple projection versions simultaneously (e.g.,
product_listing_v3andproduct_listing_v4). New application code reads from v4; old code reads from v3 until deprecated. Requires projection version lifecycle management.
For high-volume systems, shadow rebuild with blue-green cutover is the default correct choice.
Trade-offs
Single Database vs. Separate Read Store
A single-database CQRS implementation (separate query layer, same physical database) has zero eventual consistency lag. Reads see committed writes immediately. The cost is that write-model schemas and read patterns influence each other: adding an index to serve a read query adds write overhead to the write path. Scaling the read layer independently of the write layer is not possible.
A separate read store eliminates this coupling. Elasticsearch for full-text search, Redis for low-latency key lookups, a read-replica for complex relational queries — each can be scaled and optimised independently. The cost is the consistency window and the operational overhead of maintaining multiple stores and the event pipeline between them.
The decision criterion: if your read requirements fundamentally differ from your write model structure (e.g., full-text search, geospatial queries, graph traversal) or your read-to-write ratio exceeds 20:1, separate read stores pay dividends. Otherwise, a single-database CQRS implementation is simpler and sufficient.
The Temptation of the Universal Projection
A common anti-pattern: building a single "everything" projection that contains all fields any possible query might need, to avoid the overhead of building multiple projections. This projection grows without bound. It becomes slow to update, difficult to change, and eventually just as denormalised and complex as the original write model it was supposed to replace. Each read model should be scoped to a specific UI screen, report, or API contract, not designed as a general-purpose data store.
Code
The following C# example demonstrates a clean command handler using MediatR, where the write model enforces invariants and publishes domain events for downstream projection consumers.
// Command definition — no return value (fire-and-confirm, not fetch-and-return)
public record PlaceOrderCommand(
Guid CustomerId,
Guid CartId,
ShippingAddress ShippingAddress) : IRequest<PlaceOrderResult>;
public record PlaceOrderResult(Guid OrderId, OrderStatus Status);
public class PlaceOrderCommandHandler : IRequestHandler<PlaceOrderCommand, PlaceOrderResult>
{
private readonly IOrderRepository _orderRepository;
private readonly ICartRepository _cartRepository;
private readonly IDomainEventPublisher _eventPublisher;
private readonly ILogger<PlaceOrderCommandHandler> _logger;
public PlaceOrderCommandHandler(
IOrderRepository orderRepository,
ICartRepository cartRepository,
IDomainEventPublisher eventPublisher,
ILogger<PlaceOrderCommandHandler> logger)
{
_orderRepository = orderRepository;
_cartRepository = cartRepository;
_eventPublisher = eventPublisher;
_logger = logger;
}
public async Task<PlaceOrderResult> Handle(
PlaceOrderCommand command,
CancellationToken cancellationToken)
{
var cart = await _cartRepository.LoadAsync(command.CartId, cancellationToken);
if (cart == null || cart.CustomerId != command.CustomerId)
throw new InvalidCommandException($"Cart {command.CartId} not found or does not belong to customer.");
if (!cart.HasItems)
throw new InvalidCommandException("Cannot place an order for an empty cart.");
// Write model enforces business invariants
var order = Order.Create(
orderId: Guid.NewGuid(),
customerId: command.CustomerId,
lineItems: cart.LineItems,
shippingAddress: command.ShippingAddress,
placedAt: DateTimeOffset.UtcNow);
await _orderRepository.SaveAsync(order, cancellationToken);
// Publish domain events for projection consumers — AFTER the write is committed
foreach (var domainEvent in order.DomainEvents)
{
await _eventPublisher.PublishAsync(domainEvent, cancellationToken);
}
_logger.LogInformation(
"Order {OrderId} placed for customer {CustomerId}",
order.Id, command.CustomerId);
return new PlaceOrderResult(order.Id, order.Status);
}
}
The read side uses a dedicated query handler that reads directly from the denormalised projection store, with no access to the write model:
// Query definition — returns denormalised read model
public record GetOrderHistoryQuery(Guid CustomerId, int PageNumber, int PageSize)
: IRequest<PagedResult<OrderSummaryReadModel>>;
public class GetOrderHistoryQueryHandler
: IRequestHandler<GetOrderHistoryQuery, PagedResult<OrderSummaryReadModel>>
{
private readonly IOrderSummaryProjectionRepository _projectionRepository;
private readonly ILogger<GetOrderHistoryQueryHandler> _logger;
public GetOrderHistoryQueryHandler(
IOrderSummaryProjectionRepository projectionRepository,
ILogger<GetOrderHistoryQueryHandler> logger)
{
_projectionRepository = projectionRepository;
_logger = logger;
}
public async Task<PagedResult<OrderSummaryReadModel>> Handle(
GetOrderHistoryQuery query,
CancellationToken cancellationToken)
{
// Reads from pre-computed, denormalised projection — no joins, no business logic
var results = await _projectionRepository.GetByCustomerAsync(
customerId: query.CustomerId,
pageNumber: query.PageNumber,
pageSize: query.PageSize,
cancellationToken: cancellationToken);
_logger.LogDebug(
"Order history query returned {Count} records for customer {CustomerId} (page {Page})",
results.Items.Count, query.CustomerId, query.PageNumber);
return results;
}
}
// The read model is shaped for the UI — not normalised for the write model
public record OrderSummaryReadModel(
Guid OrderId,
DateTimeOffset PlacedAt,
string StatusDisplayText, // Computed from status enum — write model doesn't do this
decimal TotalAmount,
string ShippingCity, // Denormalised from address — avoids join
int ItemCount,
string PrimaryItemName, // First item's name — avoids item detail join
string? TrackingNumber); // From shipping service — sourced from a different aggregate
// Projection builder — consumes events and maintains the read model
public class OrderSummaryProjectionBuilder :
IHandleEvent<OrderPlacedEvent>,
IHandleEvent<OrderShippedEvent>,
IHandleEvent<OrderCancelledEvent>
{
private readonly IOrderSummaryProjectionRepository _repository;
public OrderSummaryProjectionBuilder(IOrderSummaryProjectionRepository repository)
{
_repository = repository;
}
public async Task HandleAsync(OrderPlacedEvent @event, CancellationToken ct)
{
var projection = new OrderSummaryReadModel(
OrderId: @event.OrderId,
PlacedAt: @event.OccurredAt,
StatusDisplayText: "Order Placed",
TotalAmount: @event.TotalAmount,
ShippingCity: @event.ShippingAddress.City,
ItemCount: @event.LineItems.Count,
PrimaryItemName: @event.LineItems.First().ProductName,
TrackingNumber: null);
await _repository.UpsertAsync(projection, ct);
}
public async Task HandleAsync(OrderShippedEvent @event, CancellationToken ct)
{
await _repository.UpdateAsync(@event.OrderId, p => p with
{
StatusDisplayText = "Shipped",
TrackingNumber = @event.TrackingNumber
}, ct);
}
public async Task HandleAsync(OrderCancelledEvent @event, CancellationToken ct)
{
await _repository.UpdateAsync(@event.OrderId, p => p with
{
StatusDisplayText = $"Cancelled — {@event.CancellationReason}"
}, ct);
}
}
The OrderSummaryReadModel record is deliberately shaped for the UI display contract, not for the write model's domain structure. StatusDisplayText, ShippingCity, and PrimaryItemName are all denormalised fields that would require joins or enum-to-string conversion at query time in a non-CQRS system. Here, they are computed once at write time and stored on the projection.